
12:30PM Thurs 29th March 2018 – the Data Centre where our equipment is located are currently experiencing a total loss of network across a big part of their facility. If you VPS is currently unreachable, please stand by, we are monitoring updates form the DC, who are working to restore service, and will post an update here as soon as we have an update from them.
Update 13:18 – We have received the following update from the Data Centre: “There has been a break in our fibre network. This is affecting customers with services in our Glasgow, Edinburgh and Manchester data centres. Our team is working to fix the problem but at the moment we don’t know how long this will take. Apologies to all affected.”
Update: 13:47 – We have received the following update from the Data Centre: “We are currently experiencing fibre issues on our national network ring. Our technicians and network suppliers (Zayo) are aware of the issue and are working towards a resolution. We are in touch with our dark fibre team who are assisting with both faults on each side of the country. This will be affecting customers with services in our Northern part of the ring (Glasgow, Edinburgh, Manchester, St Asaph). We are working hard to get services back to normal but at the moment there is no information on when that will be. Apologies to the customers being affected.”
Update 13:57 – The fibre in question is supplied to our Data Centre by a huge fibre company called Zayo, who own 204,371 km of fibre across North America and Europe, so rest assured the people working to fix the problem are more than capable. There is still no ETA on when the network will be restored unfortunately, but as soon as we have more news we’ll post it here. Apologies to all of our customers for the inconvenience we know they will be experiencing right now.
Update 14:05 – Our Data Centre have provided us with this graphic showing 2 breaks in their fibre network – just below Manchester and between Glasgow and Nottingham.
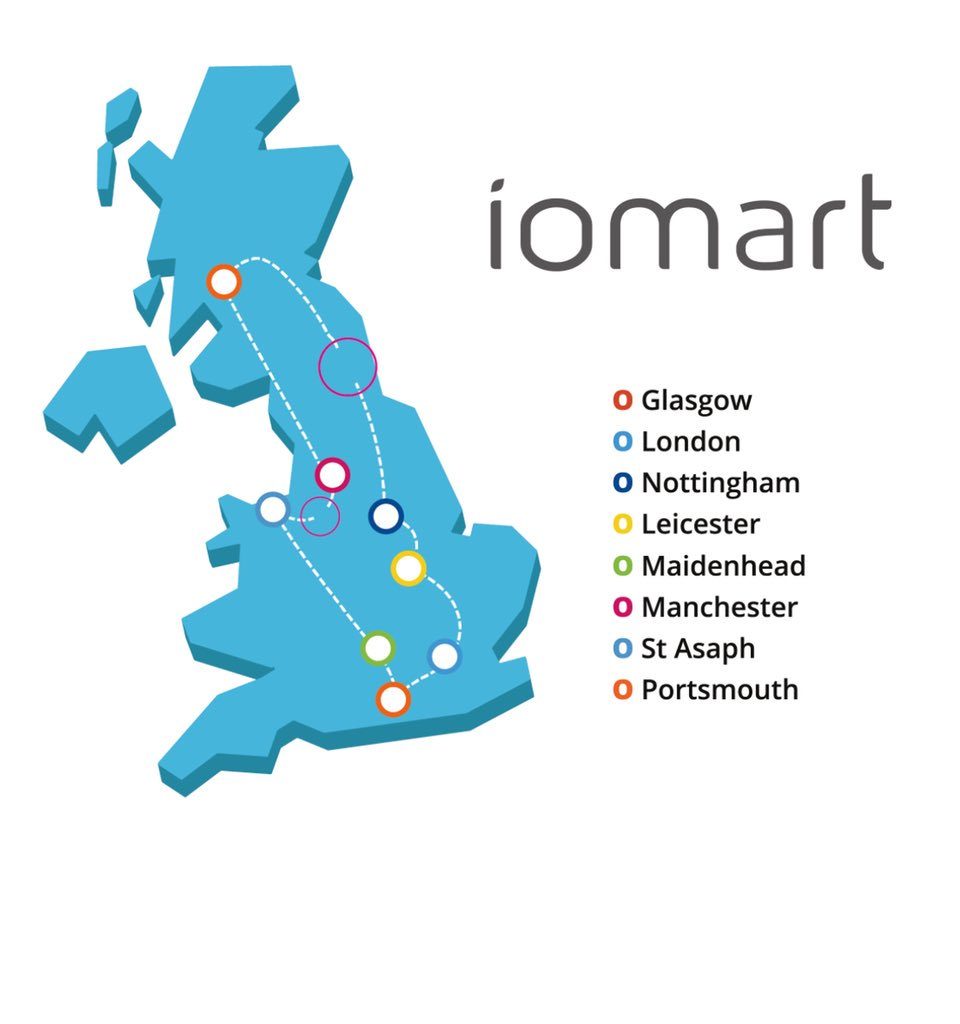
Update 14:27 – We’ve been informed that the fibre break is affecting other Data Centre providers in the UK as well as IOMart (the new name of the Data Centre we use). This is good news for us as means the incident will be being treated with the highest priority by the fibre company.
Update 15:13 – We are pleased to report that full network service has just now returned 🙂 Further info will follow…
Update 16:18 – With this incident now having been resolved, we should get a full post-mortem report from the Data Centre most likely sometime next week. We are confident this will include plans for improvements to their network to ensure something like this cannot happen again. We will share this with our customers directly when we receive this.